Quando trabalhamos com Kafka, existem alguns conceitos e palavras-chave que acabam aparecendo com bastante frequência. Antes de falar sobre cada um deles, vale a pena visualizar como a arquitetura do Kafka costuma funcionar:
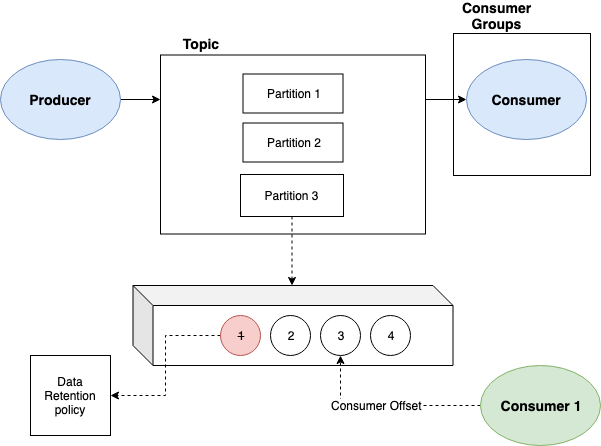
Figura 1 - Arquitetura Kafka. Fonte: RabbitMQ vs Apache Kafka
Eventos
Um evento nada mais é do que uma ação que ocorreu e foi processada pelo Kafka. Quando queremos informar um sistema sobre algo que aconteceu em outro sistema usando Kafka, estamos utilizando eventos para isso. Cada evento possui a seguinte estrutura:
- Chave: Campo obrigatório. É um identificador exclusivo para a mensagem, a chave é usada para distribuir as mensagens entre as partições do tópico, conceitos que veremos mais à frente. Se esse campo não for criado anteriormente, o próprio Kafka irá preenchê-lo.
- Value: Campo obrigatório. É o valor que aquele evento possui. Pode ser qualquer tipo de dados, como texto, binário ou JSON;
- Campos opcionais:
- Timestamp: marcação de data/hora em que a mensagem foi criada. Por default esse campo representa o momento em que a mensasgem foi criada, mas ele pode ser atualizado para quando um momento anterior, caso seja sua necessidade.
- Headers: Pares de chave-valor que podem ser usados para armazenar informações adicionais sobre a mensagem.
Abaixo, temos o exemplo de um evento do Kafka:
1 | { |
Neste exemplo, o evento processado pelo Kafka tem:
- O ID único do evento sendo 1234567890
- Mensagem “Olá, mundo!”
- O timestamp é 1696876469, o que significa que a mensagem foi criada no dia 09 de outubro de 2023, às 15:34:29 no horário de Brasília
- O Content-Type está definido como text/plain, o que significa que a mensagem está no formato “texto puro”
Tópico
Um tópico no Kafka é a forma como as mensagens são organizadas em caráter cronológico. Um tópico é organizado por dois principais itens: as mensagens e o offset de cada mensagem. O Kafka anexa cada nova mensagem no final de um tópico. Logo isso faz com o que Kafka siga uma arquitetura FIFO (first in, first out), onde os eventos são consumidos na ordem em que foram criados.
Vale lembrar que como o Kafka salva os eventos em disco no formato de log, cada mensagem é salva no final de um arquivo, igual os sistemas de log que costumamos usar em sistemas feitos em Java, por exemplo.
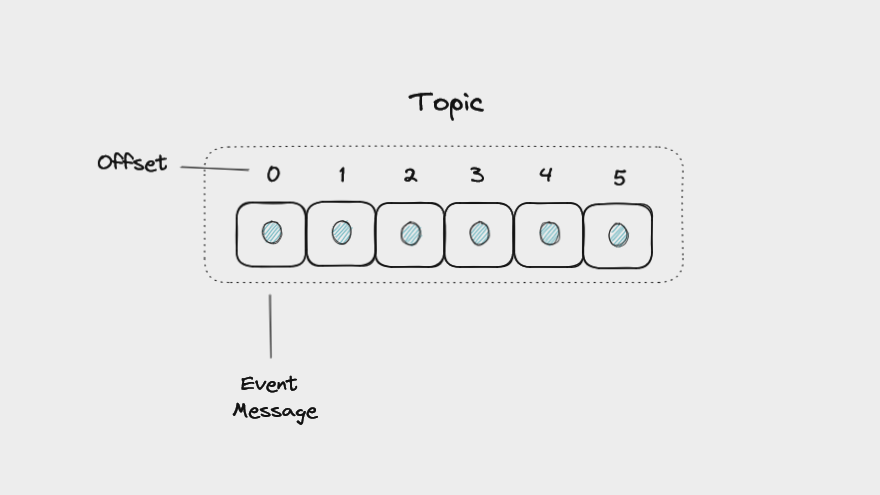
Figura 2 - Como tópicos funcionam no Kafka. Fonte: The Apache Kafka Handbook – How to Get Started Using Kafka
Produtor
Um produtor é um software que envia eventos para um tópico. Ele pode ser um microsserviço criado apenas para mandar os eventos ou um software já existente e ajustado para enviar eventos. Adicionando algumas dependências e com poucas alterações de código já é possível começar o envio desses eventos.
Alguns projetos específicos usam até mesmo hardwares para enviarem eventos. Uma empresa que monitora o clima, por exemplo, pode guardar as diferentes medições em tópicos, permitindo haver análise histórica ou a criação de gatilhos para quando determinados cenários acontecerem.
Como podemos ver na imagem abaixo, na arquitetura de eventos do Uber o aplicativo do motorista, do cliente, assim como outros serviços são produtores de eventos. Todos gravam eventos em tópicos que são consumidos por dashboards, times de debbuging e sistemas de análise em tempo real.
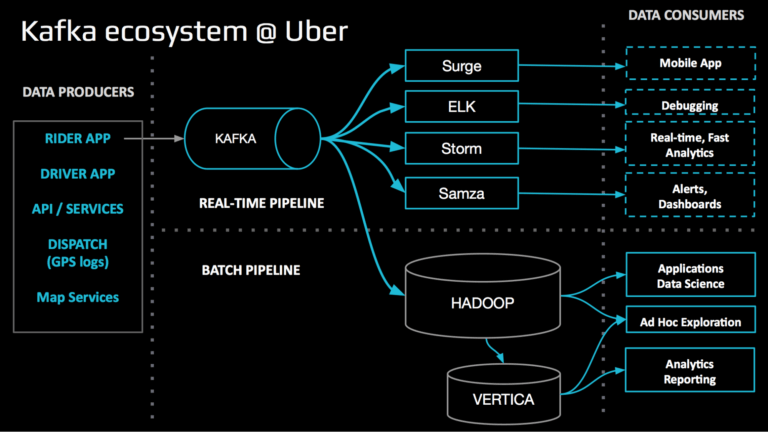
Figura 3 - Como tópicos funcionam no Kafka. Fonte: uMirrorMaker: Replicador robusto Kafka da engenharia da Uber
Consumidor
Usando o mesmo exemplo acima, podemos ver que um consumidor nada mais é do que um software conectado em tópicos, mas que ao invés de produzir acabam consumindo os eventos. Um consumidor é configurado praticamente da mesma forma que um produtor, com a diferença que a sua natureza dentro do ecossistema é diferente. É possível, até mesmo, que um mesmo software seja consumidor e produtor, tudo vai depender da arquitetura que o time de sua empresa adotará. No exemplo da Uber, vemos que existem vários consumidores lendo os eventos que foram criados durante o uso dos aplicativos da empresa pelos motoristas e passageiros.
Broker
Um broker Kafka é uma estrutura que engloba um ou mais servidores Kafka. É nele que os eventos e tópicos ficam armazenados. Pensando em arquiteturas escaláveis, podemos ter N brokers dentro de um mesmo cluster Kafka.
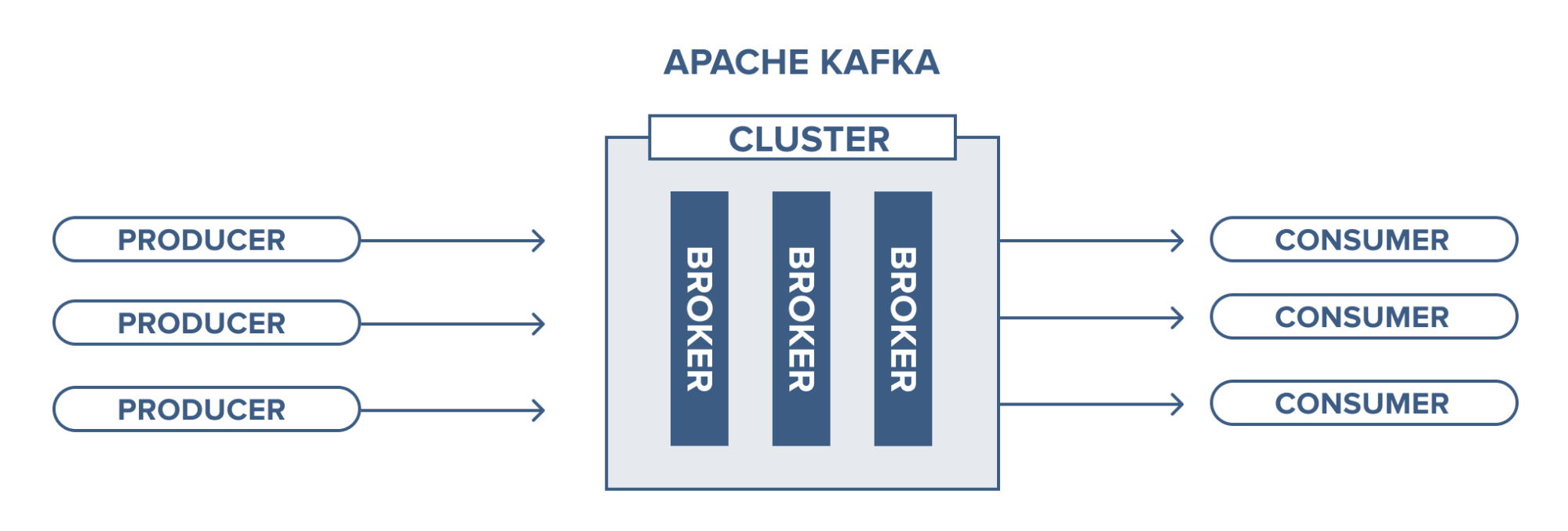
Figura 4 - Broker Kafka. Fonte: Part 1: Apache Kafka for beginners - What is Apache Kafka?
Partição
No Kafka uma partição é considerado uma cópia de um determinado tópico. Os tópicos são divididos em partições para distribuir as mensagens entre os brokers do Kafka. Cada partição é armazenada em um arquivo de log no sistema de arquivos do broker. Como vantagem, temos uma melhor distribuição de carga dentro do próprio Kafka, que armazena as mensagens e cópias de forma equilibrada dentro do broker, redundância já que as mensagens são salvas em mais de um lugar e paralelismo, permitindo que mais de um consumidor possa ler os eventos ao mesmo tempo.
Offset
Para identificar uma mensagem em uma determinada partição, usamos o offset. Um offset é um identificador único que representa a posição de uma mensagem em determinada partição. Quando um consumidor se inscreve em um tópico, ele recebe o offset inicial, que pode ser definido pelo produtor ou pelo consumidor. O consumidor então usa o offset para solicitar as mensagens do Kafka. O consumidor pode commitar o offset após consumir uma mensagem, ou seja, o Kafka saberá que a mensagem foi processada pelo consumidor. Esse processo de “avisar” o Kafka sobre o consumo da mensagem é conhecido como acknowledge. Falaremos mais sobre esse processo abaixo.
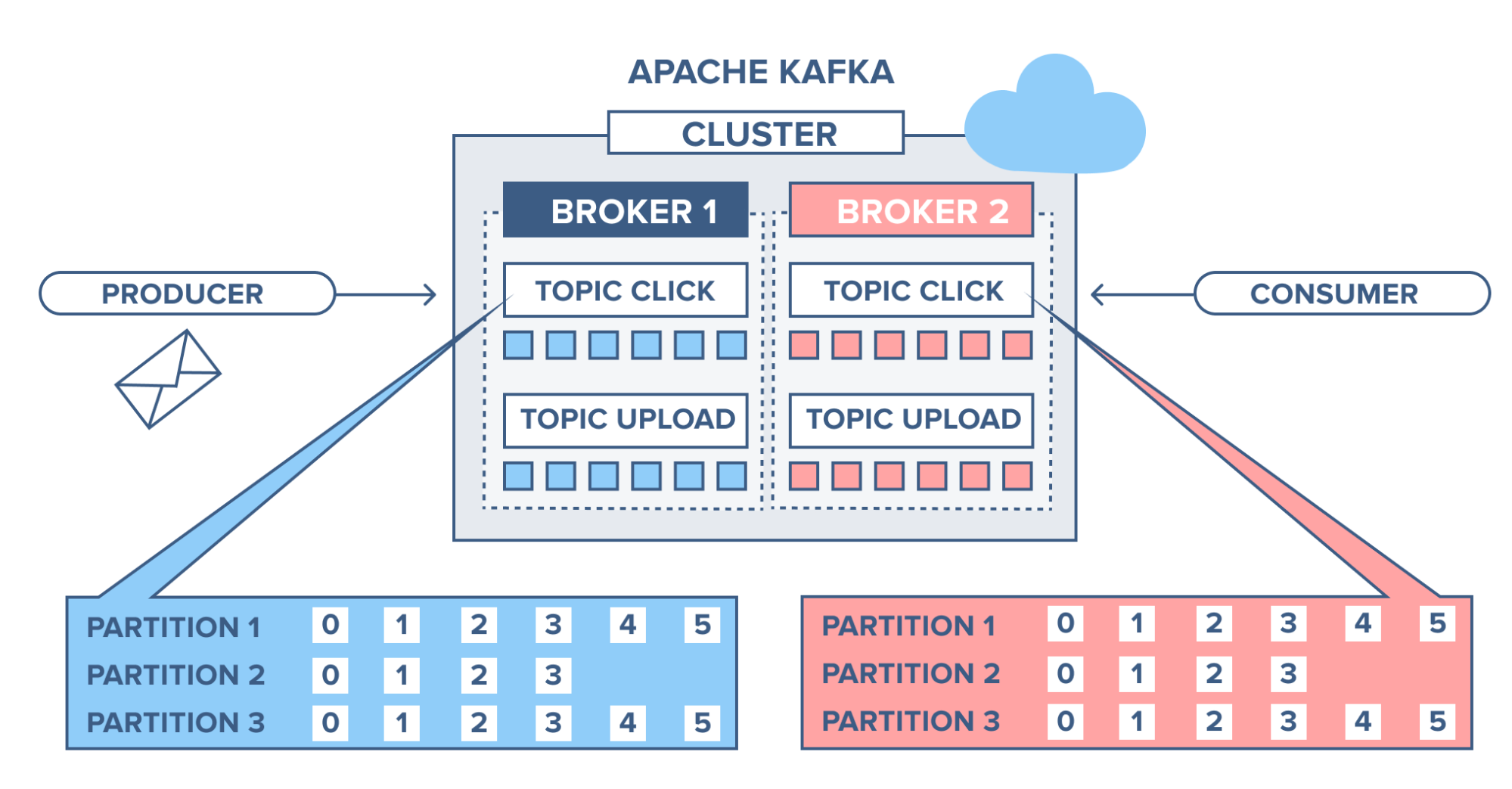
Figura 5 - Offsets e partições. Fonte: Part 1: Apache Kafka for beginners - What is Apache Kafka?
Acknowledge
O acknowledge é um processo importante para garantir que as mensagens sejam consumidas apenas uma vez e para evitar a sua perda. Existem dois tipos de acknowledge: automáticos e manuais. No automático o Kafka assume que a mensagem foi consumida com sucesso quando o consumidor a recebe. No manual, o consumidor deve enviar um acknowledge explícito ao Kafka para indicar que a mensagem foi consumida com sucesso.
Vale ressaltar que o acknowledge automático é o modo padrão de operação do Kafka. Apesar de ser simples e eficiente, não fornece garantia de que as mensagens serão consumidas apenas uma vez. No caso do acknowledge manual temos mais controle sobre o processo de consumo dos eventos. O consumidor pode escolher quando e como enviar o acknowledge. Isso pode ser útil em cenários onde é importante garantir que as mensagens sejam consumidas apenas uma vez ou quando o consumidor precisa processar as mensagens antes de enviar o acknowledge.
Consumer Groups
Os consumer groups são uma forma de organizar o consumo de eventos de um determinado tópico. Os consumidores de um mesmo grupo compartilham as mensagens daquele tópico, de modo que cada consumidor recebe apenas uma parte das mensagens. Isso ajuda na escalabilidade e resiliência do consumo, já que cada consumidor consome um pouco das mensagens, além de permitir que um consumo falho seja feito novamente por outro consumidor daquele grupo.
Os consumidores de um mesmo grupo começam a consumir as mensagens a partir do mesmo offset inicial. O Kafka garante que cada consumidor receba apenas uma parte das mensagens do tópico. Quando há o consumo de um evento, o consumidor pode commitar o offset da mensagem, processo que falamos mais ali em cima. Com isso o Kafka saberá quais consumos foram realizados por determinado consumer group.
De modo geral, acredito que esses são os principais componentes e palavras-chave que precisamos conhecer ao trabalhar com Kafka, ou pelo menos no começo das entregas com essa tecnologia. Conforme houver o aprofundamento na tecnologia, é natural que hajam novos conceitos para descobrir e ler sobre. No próximo texto planejo falar sobre os Padrões de Arquitetura que envolvem o uso de eventos, como CQRS e SAGA, por exemplo.